基础篇
什么是 ES。ES 的功能、特点、使用场景 简介:
官网:https://www.elastic.co/cn/elasticsearch/
起源:
功能:
分布式的搜索引擎,类似谷歌、百度,也可以做站内搜索。
全文检索,具有模糊搜索,相关性排名,高亮等功能。
数据分析引擎,电商网站中商品销量排名前 10 的商家、新闻网点 1 个月访问量排名前 3 的板块。
海量数据的实时处理,分布式架构可以存储和检索大量数据,秒级的数据搜索和分析
特点:
安装方便,除了 java,没有其它依赖;修改几个参数即可搭建一个集群;
JSON 格式,输入和输出都是 JSON,不需要另外定义 Schema,快捷方便;
RESTful:基本操作都可以通过 http 接口进行;
分布式,每个节点都可做入口,加入的节点自动负载均衡;
多租户,可以根据不同用途区分索引,可同时操作多个索引;
支持超大数据,可以扩展到 PB 量级的数据。
使用场景:
搜索类场景,如电商、招聘、新闻
日志分析类场景,如经典的 ELK
数据预警和数据分析,如电商中的价格预警,销售量 top10 的品牌
商业 BI 系统,数据报表、预测热卖商品、推荐系统
使用案例:
搜索方案对比 Lucene
Solr
Elasticsearch
三者共同点和区别
Solr 和 ES 是基于 Lucene 实现的。
Solr 在传统搜索应用中表现好于 ES,ES 在实时搜索应用方面好于 Solr
有哪些公司使用了 es https://elasticsearch.cn/explore/
从中文社区活动中可以看到有 华为、百度、腾讯、阿里、京东、美团、小米、今日头条、顺丰等
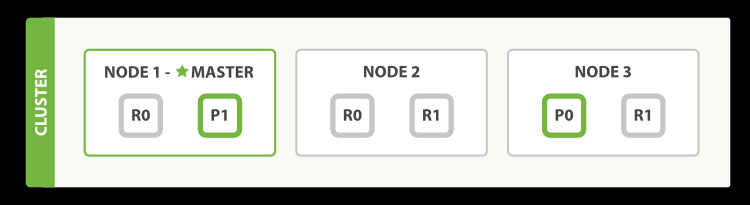
什么是 es 集群和 es 节点 节点:节点是 ES 的实例,是一个独立的进程,一般会将一个节点部署到一个服务器或虚拟机上。
按照角色分配为,master node(主节点)、data node(数据节点)、Coordinate node(协调节点)
主节点,主要职责是配置和管理集群中的节点。
数据节点,对数据的 CRUD 操作,还有搜索和聚合操作。
协调节点,将集群请求转发到主节点,将数据请求转发到数据节点
集群:ES 集群是一组连接在一起的 ES 节点实例。
集群规划策略:当前数据规模+适量增长规模。(后续可按需添加)
示例,三个节点和一个索引的集群(2 个主分片,4 个副本分片)
安装 es 需要什么组件 只需要 java 环境即可(Lucene 是基于 java 编写的)
如何安装、配置和启动
下载 ES 和 kibana: https://www.elastic.co/cn/start
创建 OS 的新用户用于启动 es 和 kibana
1 2 3 4 5 6 7 8 9 10 11 useradd estest passwd estest chown -R estest /usr/elasticsearchchown -R estest /usr/kibanasu estest
先安装 jdk,配置环境变量
安装 es、修改配置,并启动(非 root 用户启动) 验证: http://node.com:9200 ./bin/elasticsearch
再安装 kibana,修改配置、并启动(非 root 用户启动) 进入 kibana: http://node.com:5601,点击 dev_tools 项,测试。 ./bin/kibana
es 集成 IK 分词器,添加 analysis-ik 插件,ik 分词器分 ik_max_word 模式(将文本做最细粒度拆分) 和 ik_smart 模式(将文本做最粗粒度拆分)。
启动报错的话,可能需要修改最大虚拟内存数量(在 root 下进行)sysctl -a | grep vm.max_map_count
文件/etc/systel.conf
1 2 vm.max_map_count =655360
使修改生效:sysctl -p
修改 /etc/security/limits.conf,末尾追加(在 root 下进行,重新登录后生效)
1 2 3 4 * soft nofile 65536 * hard nofile 65536 * soft nproc 4096 * hard nproc 4096
Linux 修改文件句柄数及 vm.maxmap_count、stack size 的大小 运维
测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 GET _search{ "query" : { "match_all" : {} } } POST _analyze{ "analyzer" : "ik_max_word" , "text" : ["南京市长江大桥" ] } POST _analyze{ "analyzer" : "ik_smart" , "text" : ["南京市长江大桥" ] } POST _analyze{ "analyzer" : "ik_smart" , "text" : ["南京市市长" ] } PUT /lagou-es-synonym{ "settings" : { "analysis" : { "filter" : { "word_sync" : { "type" : "synonym" , "synonyms_path" : "analysis-ik/synonym.txt" } }, "analyzer" : { "ik_sync_max_word" : { "filter" : ["word_sync" ], "type" : "custom" , "tokenizer" : "ik_max_word" }, "ik_sync_smart" : { "filter" : ["word_sync" ], "type" : "custom" , "tokenizer" : "ik_smart" } } } }, "mappings" : { "properties" : { "name" : { "type" : "text" , "analyzer" : "ik_sync_smart" , "search_analyzer" : "ik_sync_smart" } } } } POST /lagou-es-synonym/_doc/1 { "name" : "拉勾是中国专业的互联网招聘平台" } POST /lagou-es-synonym/_doc/_search{ "query" : { "match" :{ "name" : "china" } } }
什么是 Index(索引) 一个索引可以理解成一个关系型的 Table(数据库表),相类似结构的数据放在一个索引,不类似的结构放在不同索引中。
什么是 Type(类型) 代表 documet 属于 index 中的哪个类别,类似于数据库中的表,在 7.x 中弃用了这个概念,8.x 中完全删除
什么是 Mapping(映射) 定义了每个字段的类型信息,相当于关系型数据库中的表结构(Schema)
什么是 Document(文档) 存储 json 文档,相当于关系型数据库中的 Row(一行记录)
什么是 Field(字段) 存储某一具体字段,相当于关系型数据库中的 Column(列)
与关系型数据库中的术语比较
什么是 shard(分片) 将索引数据分成若干小块的过程,称为分片。
分片的作用是:当文档数据量太多,磁盘和处理能力不足,对客户端的请求响应变慢时,使用分片可以改善这些问题(吞吐量、性能)。
单台服务器无法存储大量数据,es 通过分片将数据分散到多个服务器,(也就是说可以横向扩展)
什么是 replica(副本),有什么好处? 副本是对分片的拷贝,当在高负载下可以提高查询的吞吐量,也能用来实现高可用。
高可用:当主分片出现问题时,副本可以用来替换主分片,保证集群高可用。
默认情况下,每个索引有 10 个分片,5 个主分片,5 个副本分片
什么是倒排索引 倒排索引,即关键词到文档 ID 的映射,每个关键词都对应有一组文档(每个文档中都有这个关键词),有了倒排索引,就可以很方便用户搜索。
每个文档都有对应的文档 ID,文档就可以被表示为一系列的关键词。
这些文档是通过分词器,提取出出现次数和位置等内容得到关键词信息。
倒排索引中两个重要细节:
倒排索引中的所有词项对应一个或多个文档。
倒排索引中的词项,是根据字典序排列。
正向索引:从索引库中依次遍历所有文档,从文档中查找关键词,根据打分规则打分,然后排出名次,再返回。
相比正向索引对每个文档的关键字遍历过程,倒排索引是通过关键字找到文档的过程。
什么是 ik 分词器,作用是什么 ik 分词器,是基于 java 语言的中文分词工具包。
ik 分词器 3.0 特性
高处理能力。采用特有的“正向迭代最细粒度切分算法”,具有 60 万字/秒的处理能力
多子处理器分析模式。支持英文字母、数字、中文词汇等分词处理。
优化词典存储,更小的内存占用。支持扩展词典
提高了命中率。针对 Lucene 全文检索优化的查询分析器 KQueryParser,采用歧义分析算法优化查询关键字的搜索搜索排列组合。分享 IKAnalyzer 3.0 中文分词器
DocValues 是什么,有什么作用 DocValue 是一种列式存储结构,主要作用是解决字段值排序、聚合等问题(倒排索引对于检索性能好,但是对字段值排序却不理想)
搜索的时候,需要快速得到结果集
排序的时候,需要将正排索引(转置倒排索引,可以看作以文档为维度,实现根据指定字段的排序和聚合功能)
es 中的 DocValue 是默认激活的,在索引的时候创建,当字段索引时,为了快速检索,会把字段值加入到倒排索引中,同时他它也会存储字段的 DocValues。
应用场景:排序、聚合、过滤、脚本计算
当 docValues 远大于节点的可用内存时,OS 会将 doc values 放在内存中。
当 docValues 远小于节点的可用内存时,OS 会将 doc values 放在页缓存中,避免 jvm 堆内存溢出异常。
Doc Values 介绍 | Elasticsearch: 权威指南 | Elastic
倒排索引和 UN 倒排索引 | Doc Values | Elasticsearch: 权威指南 | Elastic
text 和 keyword 的区别是什么 keyword 和 text 类型的主要区别是「是否分词」.
keyword 是不会分词的,是直接根据字符串的内容来建立倒排索引(只能通过精确值搜索到)。
text 是会分词的,在存入 text 类型的值时,会先分词,然后再建立倒排索引。
什么是停顿词过滤 没有意义的一类词,可以过滤掉的词。如「的」、「而」等等
query 和 filter 的区别是什么 query: 不仅仅用于查询,还会计算分值,用于确定相关度。
filter: 仅查询,不会计算分值,也不会排序,结果可以缓存(提高性能)
操作-定义、列出、更新、删除索引的语法 索引,类似于关系型数据库中的 database,有了索引才可以创建其它内容。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 # 创建-语法 PUT /索引名称{ "settings" : { "属性名" : "属性值" } } # 创建-示例 PUT /lagou-company-index# 判断索引是否存在-语法 HEAD /索引名称# 判断索引是否存在-示例 HEAD /lagou-company-index# 查看索引-语法 GET /索引名称# 查看索引-示例 GET /lagou-company-index# 批量查看索引(用英文逗号隔开) GET /索引名称1 ,索引名称2 # 查看所有索引 # 方式1 GET _all# 方式2 ,状态意义:绿色,分片都正常分配;黄色,至少有一个副本没有正确分配;红色,至少有一个主分片没有正确分配。 GET /_cat/indices?v# 打开和关闭索引:一旦索引被关闭,这个索引就只能显示元数据信息,不能做读写操作。 # 打开索引-语法 POST /索引名称/_open# 打开索引-示例 POST /lagou-company-index/_open# 关闭索引-语法 POST /索引名称/_close# 关闭索引-示例 POST /lagou-company-index/_close# 删除索引-语法 DELETE /索引名称1 ,索引名称2 ,索引名称3 # 删除索引-示例 DELETE /lagou-company-index,lagou-employee-index
操作-定义、列出、更新、删除映射 索引创建后,就可以对字段设置约束信息,即字段映射(mapping)。
约束信息包括有:字段的数据类型、是否存储、是否索引、分词器
注意:
我们可以增加一个映射,但不能修改已存在的映射。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 # 创建映射-语法 PUT /索引库名/_mapping{ "properties" : { "字段名" : { "type" : "类型" , # 可以是 text, long, short, date, integer, date等 "index" : true , # 是否索引,默认true ;false 时,不能搜索 "store" : true , # 是否独立存储, 默认false ;独立存储时解析速度快,会占用更多的内存 "analyzer" : "分词器" # 指定分词器中文中会 } } } # 创建映射-示例 PUT /lagou-company-indexPUT /lagou-company-index/_mapping{ "properties" : { "name" : { "type" : "text" , "analyzer" : "ik_max_word" }, "job" : { "type" : "text" , "analyzer" : "ik_max_word" }, "logo" : { "type" : "keyword" , "index" : "false" }, "payment" : { "type" : "float" } } } # 查看映射关系-语法 GET /索引名称/_mapping# 查看映射关系-示例 GET /lagou-company-index/_mapping# 查看所有索引映射关系 # 方式1 GET _mapping# 方式2 GET _all/_mapping# 修改索引映射关系-语法 PUT /索引名称/_mapping{ "properties" : { "type" : "类型" , "index" : true , "store" : true , "analyzer" : "分词器" } } # 修改索引映射关系-示例(新增一个age映射) PUT /lagou-company-index/_mapping{ "properties" : { "age" : { "type" : "text" } } }
操作-定义、列出、更新、删除文档 文档,类似于关系型数据库中的一行记录。
是索引库中的数据,这些数据会根据索引规则创建索引,将来用于搜索。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 # 新增文档(可以手动指定id,也可以自动生成id) # 新增文档,手动指定id-语法 POST /索引名称/_doc/{id}{ "属性名" : "值" } # 新增文档,手动指定id-示例 POST /lagou-company-index/_doc/1 { "name" : "百度" , "job" : "小度用户运营经理" , "payment" : "30000" , "logo" : "https://www.baidu.com/img/PCfb_5bf082d29588c07f842ccde3f97243ea.png" } # 新增文档,自动生成id-语法 POST /索引名称/_doc{ "属性名" : "值" } # 新增文档,自动生成id-示例 POST /lagou-company-index/_doc{ "name" : "百度" , "job" : "算法工程师" , "payment" : "50000" , "logo" : "https://www.baidu.com/img/PCfb_5bf082d29588c07f842ccde3f97243ea.png" } # 查看单个文档-语法 GET /索引名称/_doc/{id}# 查看单个文档-示例 GET /lagou-company-index/_doc/1 # 查看所有文档-语法 POST /索引名称/_search{ "query" : { "match_all" : { } } } # 查看所有文档-示例 POST /lagou-company-index/_search{ "query" : { "match_all" : { } } } # 查看文档-通过_source定制返回结果(指定source中的返回字段,多个字段之间用逗号隔开) GET /lagou-company-index/_doc/1 ?_source=name,job# 更新文档分全部更新和局部更新。全部更新,是把之前的文档删除了(先标记删除,后台随后清理),然后再添加;局部更新,是指修改某个字段。 # 更新文档之全部更新,同添加文档一样,只是将POST 换成了PUT ,并带上了id值,存在则更新,不存在则添加 PUT /lagou-company-index/_doc/1 { "name" : "百度1" , "job" : "小度用户运营经理" , "payment" : "30000" , "logo" : "https://www.baidu.com/img/PCfb_5bf082d29588c07f842ccde3f97243ea.png" } # 更新文档之局部更新-语法 POST /索引名称/_update/{id}{ "doc" : { "field" : "value" } } # 更新文档之局部更新-示例 POST /lagou-company-index/_update/1 { "doc" : { "payment" : "60000" } } # 删除文档-语法 DELETE /索引名称/_doc/{id}# 删除文档-示例 DELETE /lagou-company-index/_doc/1 # 根据查询条件删除-语法 POST /索引名称/_delete_by_query{ "query" : { "match" : { "字段名" : "搜索关键字" } } } # 根据查询条件删除-示例 POST /lagou-company-index/_delete_by_query{ "query" : { "match" : { "name" : "百度1" } } } # 删除所有文档-语法 POST /索引名/_delete_by_query{ "query" : { "match_all" :{} } } # 删除所有文档-示例 POST /lagou-company-index/_delete_by_query{ "query" : { "match_all" : {} } } # 全量替换文档,同「更新文档之全部更新」 PUT /lagou-company-index/_doc/1 { "name" : "百度1" , "job" : "小度用户运营经理" , "payment" : "30000" , "logo" : "https://www.baidu.com/img/PCfb_5bf082d29588c07f842ccde3f97243ea.png" } # 强制创建,如果存在时不想替换,不存在时才创建 PUT /lagou-company-index/_doc/1 /_create# 或者 PUT /lagou-company-index/_doc/1 ?op_type=create { "payment" : "30000" , }
操作-执行搜索有哪些方法 方式 1(最常用):基于 DSL 检索 Elasticsearch provides a full Query DSL (Domain Specific Language) based on JSON to define queries
1 2 3 4 5 6 7 8 9 10 GET /lagou-company-index/_search{ "query" : { "bool" : { "filter" : [ {"match" : {"name" : "百度1" }} ] } } }
方式 2: 基于 URL 检索
1 GET /lagou-company-index/_search?q =name:百度2
方式 3(不推荐):类 SQL 检索
1 2 3 4 POST /_sql?format=txt{ "query" : "SELECT * FROM lagou-compony-index" }
Query DSL 支持哪些类型的查询 ES 提供了基于 JSON 的完整查询 DSL 来定义查询。
将 DSL 视为查询的 AST(抽象语法树),由叶子查询子句和复合查询子句组成。
叶子查询子句 :
叶子查询,在特定域中寻找特定的值,如 match , term 和 range
「精确匹配」包括:term , exists, term set, range , prefix, ids , wildcard, regexp, fuzzy 等等
「全文检索」匹配:match , match_phrase, multi_match, match_phrase_prefix, query_string 等等
复合查询子句
复合查询子句,包装了其它的叶子查询或复合查询,并用逻辑方式组合多个查询(如 bool 和 dis_max 查询),或更改行为(如,constant_score 查询)
Constant score query
包装一个查询,并且返回所有与相关分值等于 boost 参数的结果。
Wraps a filter query and returns every matching document with a relevance score equal to the boost parameter value.
1 2 3 4 5 6 7 8 9 10 11 GET /_search{ "query" : { "constant_score" : { "filter" : { "term" : { "user.id" : "kimchy" } }, "boost" : 1.2 } } }
Boolean query
bool 的 occurrence types 有: must, filter, should, must_not
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 POST _search{ "query" : { "bool" : { "must" : { "term" : { "user.id" : "kimchy" } }, "filter" : { "term" : { "tags" : "production" } }, "must_not" : { "range" : { "age" : { "gte" : 10 , "lte" : 20 } } }, "should" : [ { "term" : { "tags" : "env1" } }, { "term" : { "tags" : "deployed" } } ], "minimum_should_match" : 1 , "boost" : 1.0 } } }
带排序的查询
相关性排序、字段值排序、组合排序
示例:
1 2 3 4 5 6 7 8 9 10 11 POST /book/_search{ "query" : { "match_all" : {} }, "sort" : [ {"_score" : { "order" : "asc" }} {"price" : { "order" : "desc" }}, {"timestamp" : {"order:" : "desc" }} ] }
带分页的查询
1 2 3 4 5 6 7 8 9 10 11 POST /book/_search{ "query" : { "match_all" : {} }, "size" : 2 , "from" : 0 } # size : 每页显示多少页 # from : 从当前页的起始索引位置。 from = (pageNum - 1 ) * size
带高亮的查询
1 2 3 4 5 6 7 8 9 10 11 12 13 POST /lagou-company-index/_search{ "query" : { "match" : { "name" : "百" } }, "highlight" : { "pre_tags" : "<font color='red'>" , "post_tags" : "</font>" , "fields" : [{"name" :{}}] } }
批量查询
批量操作可以减少网络开销
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 # 不同索引下 GET /_mget{ "docs" : [ { "_index" : "lagou-company-index" , "_id" : 1 }, { "_index" : "lagou-exployee-index" , "_id" : 3 } ] } # 同一索引下 GET /lagou-company-index/_mget{ "docs" : [ { "_id" : 1 }, { "_id" : 3 } ] } # 或 POST /lagou-company-index/_search{ "query" : { "ids" : {"values" : ["1" ,"3" ]} } }
批量增删改
将一系列的增删改操作,通过一条请求完成,减少网络开销。
语法:
1 2 3 POST /_bulk{"action" : {"metadata" }} {"data" }
detete 不需要请求体
格式,每个 json 不能换行;相邻 json 必须换行。
示例
1 2 3 4 5 6 POST /_bulk{ "delete" : { "_index" : "book" , "_id" : "1" }} { "create" : { "_index" : "book" , "_id" : "5" }} { "name" : "test14" ,"price" :100.99 } { "update" : { "_index" : "book" , "_id" : "2" }} { "doc" : {"name" : "test" } }
资料 【金山文档】 ElasticSearch https://kdocs.cn/l/cpGSu8K35cQk Elasticsearch: 权威指南 | Elastic