在Github提交pr
在 github 提交 pr
- fork 一份到自己的仓库
- 设置本地的 origin url:
git remote set-url origin https://github.com/lyloou/WeexErosFramework.git
1 | # 查看默认上游的远程信息 |
进入自己 fork 的项目
有个
new pull request按钮,按照提示进行即可
第一次参与开源
first-contributions/README.chs.md at master · firstcontributions/first-contributions
Android中app响应浏览器链接
ApplicationContext中弹出对话框
添加权限
1
<uses-permission android:name="android.permission.SYSTEM_ALERT_WINDOW" />
显示对话框
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20private static void showRestartDialog(final Context context) {
AlertDialog.Builder builder = new AlertDialog.Builder(context, R.style.Theme_AppCompat_Light_Dialog);
builder.setMessage("应用已更新完毕,是否立即重启 ?").setCancelable(false)
.setPositiveButton("是", new DialogInterface.OnClickListener() {
public void onClick(DialogInterface dialog, int id) {
Intent intent = context.getPackageManager().getLaunchIntentForPackage(context.getPackageName());
intent.addFlags(Intent.FLAG_ACTIVITY_CLEAR_TOP);
context.startActivity(intent);
}
})
.setNegativeButton("否", new DialogInterface.OnClickListener() {
public void onClick(DialogInterface dialog, int id) {
dialog.cancel();
}
});
AlertDialog alert = builder.create();
alert.setCancelable(false);
alert.getWindow().setType(WindowManager.LayoutParams.TYPE_SYSTEM_ALERT); // Attention it!
alert.show();
}
参考资料
Java8
- https://github.com/winterbe/java8-tutorial
- http://winterbe.com/posts/2014/07/31/java8-stream-tutorial-examples/
Optional
需要返回值时
Optional.orElse
Optional.orElseThrow
不需要返回值时
Optional.ifPresent
LocalDate to TimeStamp
1 | ZoneId zoneId = ZoneId.of("Asia/Shanghai"); |
String to TimeStamp
1 | String time = "2018-12-12" |
list to map
Java8 中 List 转 Map(Collectors.toMap) 使用技巧_Hern_16 的博客-CSDN 博客
1 | // 简单对象 |
聊聊 Java8 以后各个版本的新特性 - 掘金
A categorized list of all Java and JVM features since JDK 8 to 17 - Advanced Web Machinery
Java 9 到 16 的语言和 JVM 特性更新分类清单 | NanoNova’s cyberspace
Maven
Run Your Maven Build Anywhere with the Maven Wrapper
mvn -N io.takari:maven:wrapper -Dmaven=3.6.3
Guide to installing 3rd party JARs
http://maven.apache.org/guides/mini/guide-3rd-party-jars-local.html
pom.xml 文件 中 dependency 标记的 scope 属性解释:
compile,缺省值,适用于所有阶段,会随着项目一起发布。
provided,类似 compile,期望 JDK、容器或使用者会提供这个依赖。如 servlet.jar。
runtime,只在运行时使用,如 JDBC 驱动,适用运行和测试阶段。
test,只在测试时使用,用于编译和运行测试代码。不会随项目发布。
system,类似 provided,需要显式提供包含依赖的 jar,Maven 不会在 Repository 中查找它。
1 | <!-- 如:system --> |
一键生成
1 | mvn archetype:generate -DgroupId=com.lyloou.app -DartifactId=algs4 -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false |
多模块开发
- Maven 构建简单的多模块项目 - CN.programmer.Luxh - 博客园
- 基于 Maven 分模块开发实践 - 郭恩洲的个人页面 - OSCHINA
- Maven 最佳实践:划分模块 - Maven 中文 - ITeye 博客
nexus 安装
nexus2
【原创】Nexus 搭建 Maven 私服
https://help.sonatype.com/repomanager2/installing-and-running/running
注意访问网址是: http://localhost:8081/nexus/
学习建议:mvn 这个东西,就是难者不会,会者不难。基本上按照这样一个路线就问题不大,基本使用 => 了解继承/聚合 => 了解 jar 包冲突机制,并解决冲突 =>了解 mvn 的 3 个默认声明周期 ,生命周期的各个阶段 phase ,各个阶段的目标 goal => mvn 的插件开发 => Nexus 私服搭建及其使用。大致这样一个过程下来,就能非常熟悉 mvn,如果在稍微看看 mvn 的源码,大致看一看,基本上可以说是精通 mvn 了。
nexus3
https://help.sonatype.com/repomanager3/download/download-archives---repository-manager-3
1 | docker volume create --name nexus-data |
https://www.cnblogs.com/EasonJim/p/6858333.html
1 | nexus.exe /install <optional-service-name> #安装 |
- 使用 Maven 管理 Java 项目 - 大梦初晓 - SegmentFault 思否
- 理解 Maven 中的 SNAPSHOT 版本和正式版本 - 黄博文的地盘
- Maven - 快照 - Maven 教程 - 极客学院 Wiki
快照 vs 版本
对于版本,Maven 一旦下载了指定的版本(例如 data-service:1.0),它将不会尝试从仓库里再次下载一个新的 1.0 版本。想要下载新的代码,数据服务版本需要被升级到 1.1。
对于快照,每次用户接口团队构建他们的项目时,Maven 将自动获取最新的快照(data-service:1.0-SNAPSHOT)。
设置 deploy 的地址
1 | <!-- pom.xml中加入 --> |
有一些与 Maven 生命周期相关的重要概念需要说明
当一个阶段通过 Maven 命令调用时,例如 mvn compile,只有该阶段之前以及包括该阶段在内的所有阶段会被执行。
不同的 maven 目标将根据打包的类型(JAR / WAR / EAR),被绑定到不同的 Maven 生命周期阶段。
maven dependency 中 scope=compile 和 provided 区别
maven 中三种 classpath
编译,测试,运行
1.compile:默认范围,编译测试运行都有效
2.provided:在编译和测试时有效
3.runtime:在测试和运行时有效
4.test:只在测试时有效
5.system:在编译和测试时有效,与本机系统关联,可移植性差
multiple conflict
maven 2 - SLF4J: Class path contains multiple SLF4J bindings - Stack Overflow
1 | <exclusions> |
Generate source code jar for Maven based project – Mkyong.com
1 | <build> |
1 | # 查看 goal 和 phase 的默认绑定 |
打包的时候,resource 中的文件没有打包进去
1 | mvn resources:resources |
Apache Maven Resources Plugin – Filtering
其他镜像
maven 加速
1 | <!-- --> |
idea 中调用 compile, package 时跳过测试
1 | <properties> |
Maven 如何为不同的环境打包 —— 开发、测试和产品环境 - 作业部落 Cmd Markdown 编辑阅读器
1 | <profile> |
上传到 公网 maven repository
https://maven.apache.org/repository/guide-central-repository-upload.html
https://central.sonatype.org/pages/ossrh-guide.html
https://central.sonatype.org/pages/apache-maven.html
https://central.sonatype.org/publish/requirements/gpg
发布构件到 Maven 中央仓库 - 在风中的个人空间 - OSCHINA - 中文开源技术交流社区
mvn clean deploy -P release -Dgpg.passphrase=密码
mvn clean deploy -Pdeploy
How to Deploy only the sub-modules using maven deploy? - Stack Overflow
mvn deploy -pl SubModuleB
Docker
install
wget -qO- https://get.docker.com | sh
config
https://www.jianshu.com/p/95e397570896
``` sh
如果还没有 docker group 就添加一个:
sudo groupadd docker
将用户加入该 group 内。然后退出并重新登录就生效啦。
sudo gpasswd -a ${USER} docker
重启 docker 服务
sudo service docker restart
切换当前会话到新 group 或者重启 X 会话
newgrp - docker
注意:最后一步是必须的,否则因为 groups 命令获取到的是缓存的组信息,刚添加的组信息未能生效,所以 docker images 执行时同样有错。
```
加速器
https://www.daocloud.io
config docker preference(registry-mirrors) :
for ubuntu
curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http://6cde3c02.m.daocloud.io
sudo systemctl restart docker.service
curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http://d1d9aef0.m.daocloud.io
示例
1 | docker run hello-world |
Docker 中文教程_Docker 开发中文手册[PDF]下载-极客学院 Wiki
-d: 标示是让 docker 容器在后台运行。-P: 标示 Docker 所需的端口映射从主机映射到我们的容器内。-t: 表示在新容器内指定一个伪终端或终端,-i: 表示允许我们对容器内的 STDIN 进行交互。-p: 标识来指定容器端口绑定到主机端口 > sudo docker run -d -p 5000:5000 training/webapp python app.py > sudo ocker port nostalgic_morse 5000 > https://wiki.jikexueyuan.com/project/docker/userguide/dockerlinks.html
1 | sudo docker run -t -i training/sinatra /bin/bash |
1 | sudo docker build -t="lyloou/sinatra:v2" . |
1 | # http://wiki.jikexueyuan.com/project/docker/examples/nodejs_web_app.html |
数据持久化
如果需要数据持久化,可以使用数据卷机制。
1 | docker run -p 8080:8080 -p 50000:50000 -v /your/home:/var/jenkins_home jenkins |
or
1 | docker volume create --name jenkins_home |
docker-compose
install and run
1 | pip install docker-compose |
uninstall and remove
1 | # Stop and remove containers, networks, images, and volumes |
1 | # 获取docker服务地址 |
网络管理
Docker 错误集合_挂件-CSDN 博客_error: pool overlaps with other one on this addres
查看 docker 网卡
1 | docker network ls |
查看 docker 网卡的相关详细信息 确认是自己创建的 ip 段 然后在删除相应的网卡
1 | docker network inspect ${containerid} |
删除 docker 网卡
1 | docker network rm ${containerid} |
清除日志
https://stackoverflow.com/a/43570083
1 | truncate -s 0 /var/lib/docker/containers/*/*-json.log |
查看日志
https://blog.csdn.net/jiangyu1013/article/details/96147534
1 | docker logs -f -t --since="2017-05-31" --tail=10 edu_web_1 |
搭建私有仓库
https://yeasy.gitbook.io/docker_practice/repository/registry
停止
docker stop $(docker ps -aq)
docker-compose
1 | docker-compose ps |
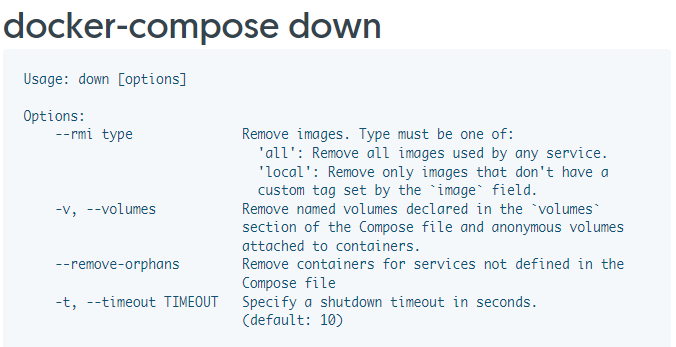
https://docs.docker.com/compose/reference/down/
1 | # rebuild demo-admin |
宿主机与容器之前的复制
容器到宿主机:docker cp container_name:/opt/abc.txt /tmp/
宿主机到容器:docker cp /tmp/abc.txt container_name:/opt/
不论容器是否启动,都可以执行上面的命令
查看容器信息
1 | docker inspect aafbdd |
Weex
学习资源
案例
问题
可能是史上最全的weex踩坑攻略
WEEX 使用navigator跳转Android系统出现ActivityNotFoundException报错
1 | <activity |
1 | String navUrl = getIntent().getData().toString(); |
分析模板代码(如下面所示):
我们需要一个mContainer来容纳已经渲染过的wxview
1 | <!-- activity_wxpage.xml --> |
1 | // AbsWeexActivity.java |
Go测试
1 | import ( |
测试扩展包(External test package):
目的:解决包的循环依赖问题。
方法:给包名添加_test后缀。
https://yar999.gitbooks.io/gopl-zh/content/ch11/ch11-02.html
1 | // 产品代码 |
像fmt/export_test.go中所表现的,通过提供一个秘密出口的小技巧,来进行测试扩展包的白盒测试。
—— https://yar999.gitbooks.io/gopl-zh/content/ch11/ch11-02.html (11.2.4)
开始一个好的测试的关键是通过实现你真正想要的具体行为,然后才是考虑简化测试代码。
最好的接口是直接从库的抽象接口开始,针对公共接口编写一些测试函数。
Mysql命令行实用程序
help
1 | mysql --help |
启动 mysql:
1 | mysql -u root -p |
导入数据结构和数据
1 | mysql -u root -p goods < goods_db_structure.sql |
Mysql 通过 cmd 命令导入 sql 文件_gaochen519 的博客-CSDN 博客
1 | mysql -uroot -p |
show
mysql show columns 等 show 的用法 - yufenfei - ITeye 博客
SHOW DATABASES︰列出 MySQL Server 上的数据库。
SHOW TABLES [FROM db_name]︰列出数据库中的表。
SHOW TABLE STATUS [FROM db_name]︰列出数据库的表信息,比较详细。
SHOW COLUMNS FROM tbl_name [FROM db_name]︰列出表的列信息,同 SHOW FIELDS FROM tbl_name [FROM db_name],DESCRIBE tbl_name [col_name]。
SHOW FULL COLUMNS FROM tbl_name [FROM db_name]︰列出表的列信息,比较详细,同 SHOW FULL FIELDS FROM tbl_name [FROM db_name]。
SHOW INDEX FROM tbl_name [FROM db_name]︰列出表的索引信息。
SHOW STATUS︰列出 Server 的状态信息。
SHOW VARIABLES︰列出 MySQL 系統参数值
SHOW PROCESSLIST︰查看当前 mysql 查询进程 (可以用来查看死锁问题)
SHOW GRANTS FOR user︰列出用户的授权命令
\g 和 \G
MySQl 中的\g 和\G - 一步一个小脚印 - 博客园
- \g
在 MySQL 的 sql 语句后加上\g,效果等同于加上定界符,一般默认的定界符是分号; - \G
在 MySQL 的 sql 语句后加上\G,表示将查询结果进行按列打印,可以使每个字段打印到单独的行。即将查到的结构旋转 90 度变成纵向;
Mysql必知必会
《MySQL 必知必会》——BenForta 著 刘晓霞译
表结构和数据源文件 http://forta.com/books/0672327120/
客户机-服务器软件
- 服务器部分是负责所有数据访问和处理的一个软件。
- 客户机是与用户打交道的软件。
例如,如果你请求一个按字母顺序列出的产品表,则客户机软件通过网络提交该请求给服务器软件。
服务器软件处理这个请求,根据需要过滤、丢弃和排序数据;然后把结果送回到你的客户机软件。
- 服务器软件为 MySQL DBMS。
- 客户机软件可以是 MySQL 提供的工具、脚本语言(如 Perl)、Web 应用开发语言(如 ASP、ColdFusion、JSP 和 PHP)、
程序设计语言(如 C、C++、Java)等。
SHOW
1 | SHOW DATABASES; |
检索
SELECT 子句及其顺序 p88
| 子句 | 说明 | 是否必须使用 |
|---|---|---|
| SELECT | 要返回的列或表达式 | 是 |
| FROM | 从中检索数据的表 | 仅在从表中选择数据时使用 |
| WHERE | 行级过滤 | 否 |
| GROUP BY | 分组说明 | 仅在按组计算聚集时使用 |
| HAVING | 组级过滤 | 否 |
| ORDER BY | 输出排序顺序 | 否 |
| LIMIT | 要检索的行数 | 否 |
1 | SELECT prod_name FROM products; |
DISTINCT
1 | SELECT DISTINCT vend_id FROM products; # DISTINCT 表示只返回唯一不同的行,用法是直接放在列名前,注意不能使用DISTINCT |
LIMIT
1 | SELECT prod_name FROM products LIMIT 5; # 返回前5行;类似 LIMIT 0,5 |
ORDER BY
关系数据设计理论认为,如果不明确规定排序,则不应该假定检索出的数据的顺序有意义。
1 | SELECT prod_name FROM products ORDER BY prod_name; |
WHERE
1 | SELECT prod_name, prod_price FROM products WHERE prod_price = 2.50; |
子句操作符
| 操作符 | 说明 |
|---|---|
| = | 等于 |
| <> | 不等于 |
| != | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| BETWEEN | 在指定的两个值之间 |
AND & OR
1 | SELECT prod_id, prod_price, prod_name FROM products WHERE vend_id = 1003 AND prod_price <= 10; # 逻辑与 |
当AND和OR在一起时,在处理OR之前,优先处理AND操作符。解决办法是使用()
1 | SELECT prod_name, prod_price FROM products WHERE vend_id = 1002 OR vend_id = 1003 AND prod_price >= 10; |
IN
1 | SELECT prod_name,prod_price FROM products WHERE vend_id IN (1002, 1003) ORDER BY prod_name; |
IN的功能与OR相当,且有更多的优点:
- 在使用长的合法选项清单时,
IN操作符的语法更清楚且更直观。 - 在使用
IN时,计算的次序更容易管理(因为使用的操作符更少) IN操作符一般比OR操作符清单执行的更快。IN的最大优点是可以包含其他SELECT语句,使得能够更容易动态地建立WHERE子句。
NOT,在WHERE子句中用来否定后跟条件的关键字
1 | SELECT prod_name, prod_price FROM products WHERE vend_id NOT IN (1002, 1003) ORDER BY prod_name; |
NOT可以和IN、BETWEEN、EXISTS子句结合使用,对结果取反。
通配符
1 | SELECT prod_id, prod_name FROM products WHERE prod_name LIKE 'jet%'; # 检索任意以jet起头的词 |
%通配符不能匹配值为NULL的行。
使用通配符的技巧:
- 不要过度使用通配符。如果其他操作符能达到相同的目的,应该使用其他操作符。
- 在确实需要使用通配符时,除非绝对有必要,否则不要把它们用在搜索模式的开始处。把通配符置于搜索模式的开始处,搜索起来是最慢的。
- 仔细注意通配符的位置。如果放错了地方,可能不会返回想要的数据。
正则表达式
1 | SELECT prod_name FROM products WHERE prod_name REGEXP '1000' ORDER BY prod_name; |
重复元字符
| 元字符 | 说明 |
|---|---|
| * | 0 个或多个匹配 |
| + | 1 个或多个匹配(等于{1,}) |
| ? | 0 个或 1 个匹配(等于{0,1}) |
| {n} | 指定数目的匹配 |
| {n,} | 不少于指定数目的匹配 |
| {n,m} | 匹配数目的范围(m 不超过 255) |
定位元字符
| 元字符 | 说明 |
|---|---|
| ^ | 文本的开始 |
| $ | 文本的结尾 |
| [[:<:]] | 词的开始 |
| [[:>:]] | 词的结尾 |
^ 有两种用法,在集合中(用[和]定义),用它来否定该集合,否则,用来指串的开始。
简单的正则表达示测试
1 | SELECT 'hello' REGEXP '[a-zA-Z]' # 验证字符是否符合正则 |
条件符合时结果为 1,条件不符合时结果为 0;
计算字段
1 | SELECT Concat(vend_name, ' (', vend_country, ')') FROM vendors ORDER BY vend_name; # 拼接字段Concatenate, 将值连接到一起构成单个值 |
MySQL 算术操作符
| 操作符 | 说明 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
数据处理
1 | SELECT vend_name, Upper(vend_name) AS vend_name_upcase FROM vendors ORDER BY vend_name; |
常用文本处理函数
| 函数 | 说明 |
|---|---|
| Left() | 返回串左边的字符 |
| Length() | 返回串的长度 |
| Locate() | 找出串的一个子串 |
| Lower() | 将串转换为小写 |
| LTrim() | 去除串左边的空格 |
| Right() | 返回串右边的字符 |
| RTrim() | 去除串右边的空格 |
| Soundex() | 返回串的 SOUNDEX 值 |
| SubString() | 返回子串的字符 |
| Upper() | 将串转换为大写 |
1 | SELECT cust_id, order_num FROM orders WHERE Date(order_date) = '2005-09-01'; |
常用日期和时间处理函数
| 函数 | 说明 |
|---|---|
| AddDate() | 增加一个日期(天、周等) |
| AddTime() | 增加一个时间 |
| CurDate() | 返回当前日期 |
| CurTime() | 返回当前日间 |
| Date() | 返回日期时间的日期部分 |
| DateDiff() | 计算两个日期之差 |
| Date_Add() | 高度灵活的日期运算函数 |
| Date_Format() | 返回一个格式化的日期或时间串 |
| Day() | 返回一个日期的天数部分 |
| DayOfWeek() | 对于一个日期,返回对应的星期几 |
| Hour() | 返回一个时间的小时部分 |
| Minute() | 返回一个时间的分钟部分 |
| Month() | 返回一个日期的月数部分 |
| Now() | 返回当前日期和时间 |
| Second() | 返回一个时间的秒部分 |
| Time() | 返回一个日期的时间部分 |
| Year() | 返回一个日期的年份部分 |
汇总数据
1 | SELECT AVG(prod_price) AS avg_price FROM products; # AVG函数只作用于单个列,为了获得多个列的平均值,必须使用多个AVG函数 |
聚集函数用来汇总数据。MySQL 支持一系列聚集函数,可以用多种方法使用它们以返回所需的结果。
这些函数是高效设计的,它们返回结果一般比你在自己的客户机应用程序中计算要快得多。
分组数据
1 | SELECT vend_id, COUNT(*) AS num_prods FROM products GROUP BY vend_id; |
GROUP BY重要规定
GROUP BY子句可以包含任意数目。这使得能对分组进行嵌套,为数据分组提供更细致的控制。- 如果在
GROUP BY子句中嵌套了分组,数据将在最后规定的分组上进行汇总换句话说,在建立分组时,指定的所有列都一起计算
(所以不能从个别的列取回数据)。 GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。
如果在 SELECT 中使用表达式,则必须在 GROUP BY 子句中指定相同的表达式。不能使用别名。 // 这个不对吧,譬如上面的第三条语句。版本升级?- 除聚集计算语句外,SELECT 语句中的每个列都必须在 GROUP BY 子句中给出。
- 如果分组列中具有 NULL 值,则 NULL 将作为一个分组返回。如果列中有多行 NULL 值它们将分为一组。
- GROUP BY 子句必须出现在 WHERE 子句之后,ORDER BY 子句之前。
子查询和联结
1 | SELECT cust_name, cust_contact |
使用联结的要点:
- 注意所使用的联结类型。一般我们使用内部联结,但使用外部联结也是有效的。
- 保证使用正确的联结条件,否则将返回不正确的数据。
- 应该总是提供联结条件,否则会得出笛卡尔积。
- 在一个联结中可以包含多个表,甚至对于每个联结可以采用不同的联结类型。虽然这样做是合法的,一般也很有用,但应该在一起测试它们前,分别测试每个联结。这将使故障排除更为简单。
组合查询
1 | SELECT vend_id, prod_id, prod_price |
UNION规则
- UNION 必须由两条或两条以上的 SELECT 语句组成,语句之间用关键字 UNION 分隔(因此,如果组合 4 条 SELECT 语句,将要使用 3 个 UNION 关键字)
- UNION 中的每个查询必须包含相同的列、表达式或聚集函数(不过各个列不需要以相同的次序列出)。
- 列数据类型必须兼容:类型不必完全相同,但必须是 DBMS 可以隐含地转换的类型(例如,不同的数值类型或不同的日期类型)。
全文本搜索
1 | SELECT note_text FROM productnotes WHERE Match(note_text) Against('rabbit'); |
MySQL 中,最常用的两个引擎为 MyISAM 和 InnoDB,MyISAM 引擎支持全文本搜索。
不要在导入数据时使用 FULLTEXT,应该首先导入数据,然后再修改表,定义 FULLTEXT。
全文本布尔操作符
| 布尔操作符 | 说明 |
|---|---|
| + | 包含,词必须存在 |
| - | 排除,词必须不出现 |
| > | 包含,而且增加等级值 |
| < | 包含,且减少等级值 |
| () | 把词组成子表达式(允许这些子表达式作为一个组实包含、排除、排列等) |
| ~ | 取消一个词的排序值 |
| * | 词尾的通配符 |
| “” | 定义一个短语(与单个词的列表不一样,它匹配整个短语以便包含或排除这个短语) |
插入 & 更新 & 删除
INSERT
1 | INSERT INTO customers(cust_name, |
总是使用列的列表:即便表的结构改变,INSERT 语句仍能正确工作。
省略列,须满足以下某个条件:
- 该列定义为允许 NULL 值(无值或空值)
- 在表定义中给出默认值。这表示如果不给出值,将使用默认值。
如果系统的数据检索是最重要的,可以降低 INSERT、UPDATE、DELETE 的优先级来提高整体性能。INSERT LOW PRIORITY INTO
UPDATE
1 | UPDATE customers |
DELETE
1 | DELETE FROM customers |
更新和删除的指导原则
- 除非确实打算更新和删除每一行,否则绝对不要使用不带 WHERE 子句的 UPDATE 或 DELETE 语句;
- 保证每个表都有主键,尽可能像 WHERE 子句那样使用它(可以指定各主键、多个值或值的范围);
- 在对 UPDATE 或 DELETE 使用 WHERE 子句前,应该先用 SELECT 进行测试,保证它过滤的是正确的记录,以防编写的 WHERE 子句不正确。
- 使用强制实施引用完整性的数据库,这样 MySQL 将不允许删除具有与其他表相关联的数据的行。
创建和操纵表
1 | CREATE TABLE customers |
引擎:
- InnoDB 是一个可靠的事务处理引擎,它不支持全文本搜索。
- MEMORY 在功能等同于 MyISAM,但由于数据存储在内在(不是磁盘)中,速度很快(特别适合于临时表)
- MyISAM 是一个性能极高的引擎,它支持全文本搜索,但不支持事务处理。
外键不能跨引擎,即使用一个引擎的表不能引用具有使用不同引擎的表的外键。
使用哪个引擎,依赖于需要什么样的特性;
1 | ALTER TABLE vendors |
使用视图
常见视图应用
- 重用 SQL 语句
- 简化复杂 SQL 操作。在编写查询后,可以方便地重用它而不必知道它的基本查询细节。
- 使用表的组成部分而不是整个表。
- 保护数据。可以给用户授予表的特定部分的访问权限而不是整个表的访问权限。
- 更改数据格式和表示。视图可返回与底层表的表示和格式不同的数据。
视图的规则和限制
- 与表一样,视图必须唯一命名(视图名不能重复或与表名相同)
- 对于可以创建的视图数目没有限制。
- 为了创建视图,必须具有足够的访问权限。这些限制通常由数据库管理人员授予。
- 视图可以嵌套,即可以利用从其他视图中检索数据的查询来构造一个视图
- ORDER BY 可以用在视图中,但如果从该视图检索数据的 SELECT 语句中也含有 ORDER BY, 那么该视图中的 ORDER BY 将被覆盖。
- 视图不能索引,也不能有关联的触发器或默认值。
- 视图可以和表一起使用。例如,编写一条联结表和视图的 SELECT 语句。
视图的创建
- 视图用 CREATE VIEW 语句来创建。
- 使用
SHOW CREATE VIEW viewname;来查看创建视图的语句。 - 用 DROP 删除视图,其语法为
DROP VIEW viewname; - 更新视图时,可以先用 DROP 再用 CREATE,也可以直接用
CREATE OR REPLACE VIEW。如果更新的视图不存在,则第 1 条语句会创建一个视图;
如果要更新的视图存在,则第 2 条更新的语句会替换原有视图。
1 | CREATE VIEW productcustomers AS |
视图定义在以下操作不可更新
- 分组(使用 GROUPING 和 HAVING)
- 联结
- 子查询
- 并
- 聚集函数(Min(), Cust(), Sum()等)
- DISTINCT
- 导出(计算)列
视图的主要作用在于数据检索,而不用于更新(INSERT、UPDATE 和 DELETE)
存储过程
为什么使用存储过程
- 通过把处理封装在容易使用的单元中,简化复杂的操作。
- 由于不要求反复建立一系列处理步骤,这保证了数据的完整性。
如果所有开发人员和应用程序都使用同一存储过程,则所使用的代码都是相同的。防止错误,保证了数据的一致性。 - 简化对变动的管理。如果表名、列名、或业务逻辑有变化,只需要更改存储过程的代码。使用这的人员甚至不需要知道这些变化。
这一点的延伸就是安全性。通过存储过程限制对基础数据的访问减少了数据讹误的机会。 - 提高性能。因为使用在座过程比使用单独的 SQL 语句要快。
- 存在一些只能用在单个请求中的 MySQL 元素和特性,存储过程可以使用它们来编写功能更强更灵活的代码。
换句话说,使用存储过程有 3 个主要好处:简单、安全、高性能。
另外也有一些缺陷:
- 存储过程的编写比 SQL 语句复杂,编写存储过程概要更高的技能,更丰富的经验。
- 由于数据库管理员限制,可能只有使用的权限,没有创建的权限。
1 | CREATE PROCEDURE productpricing( |
mysql 命令行客户机的分隔符:
mysql 命令行实用程序使用;作为分隔符
默认 mysql 语句也使用;作为分隔符
解决冲突的办法是临时更改命令行实用程序的语句分隔符
1 | DELIMITER // |
考虑这个场景。你需要获得与以前一样的订单合计,但需要对合计增加营业税,不过只针对某些顾客。
那么,你需要做下面几件事情:
- 获得合计(与以前一样);
- 把营业税有条件地添加到合计;
- 返回合计(带或不带税)
1 | -- Name: order total |
游标
MySQL 游标只能用于存储过程。
使用游标的步骤:
- 在能够使用游标前,必须声明(定义)它。这个过程实际上没有检索数据,它只是定义要使用的 SELECT 语句。
- 一旦声明后,必须打开游标以供使用。这个过程用前面定义的 SELECT 语句把数据实际检索出来。
- 对于填有数据的游标,根据需要取出(检索)各行。
- 在结束游标使用时,必须关闭游标。
1 | CREATE PROCEDURE processorders() |
触发器
触发器,在表发生一些更改时,自动处理一些事情。
MySQL 触发器只支持UPDATE、DELETE、INSERT。
创建触发器,需要给出 4 条信息:
- 唯一的触发器名;
- 触发器关联的表;
- 触发器应该响应的活动(DELETE、INSERT 或 UPDATE)
- 触发器何时执行(处理之前或之后)
1 | # http://www.cnblogs.com/duhuo/p/4655957.html |
只有表支持触发器,视图不支持
每个表支持 6 个触发器(每条 INSERT、UPDATE、DELETE 的之前和之后)
如果 BEFORE 触发器失败,则 MySQL 将不执行请求的操作。
此外,如果 BEFORE 触发器或语句本身失败,MySQL 将不执行 AFTER 触发器(如是有的话)
触发器一个非常有意义的使用是创建审计跟踪。使用触发器,把更改记录到另外一个表非常容易。
管理事务
事务处理(transaction processing) 可以用来维护数据库的完整性,它保证成批的 MySQL 操作要么完全执行,要么完全不执行。
MyISAM 引擎不支持事务,InnoDB 支持事务。
1 | SELECT * FROM ordertotals; |
全球化和本地化
1 | SHOW CHARACTER SET ; # 查看字符集 |
安全管理
MySQL 的用户账号和信息存储在名为 mysql 的 MySQL 数据库中。
1 | USE mysql; |
GRANT 和 REVOKE 可在几个层次上控制访问权限
- 整个服务器,使用 GRANT ALL 和 REVOKE ALL;
- 整个数据库,使用 ON database.*;
- 特定的表,使用 ON database.table;
- 特定的列;
- 特定的存储过程;
- 详细看 p202
数据库维护
从以下几个角度考虑
备份数据
备份前使用FLUSH TABLE表问题分析和检查
1 | ANALYZE TABLE orders; |
诊断启动问题
使用命令行选项,--help、--safe-mode、--verbose查看日志文件
https://stackoverflow.com/questions/5441972/how-to-see-log-files-in-mysql
改善性能
- 一般来说,关键的生产 DBMS 应该运行在自己的专用服务器上。
- MySQL 是用一系列默认设置预先配置的,这些设置开始通常是很好的。但过一段时间后你可能需要调整内在分配、缓冲区大小等。
(为查看当前设置,可使用 SHOW VARIABLES; 和 SHOW STATUS;) - MySQL 是一个多用户多线程的 DBMS,换言之,它经常同时执行多个任务。
如果这些任务中的某个执行缓慢,则所有请求都会执行缓慢。
如果你遇到显著的性能不良,可使用SHOW PROCESSLIST显示所有活动进程(以及它们的线程 ID 和执行时间)。
你还可以用 KILL 命令终结某个特定的进程(使用这个命令需要作为管理员登录)。 - 总是有不止一种方法编写同一条 SELECT 语句。应该试验联结、并、子查询等,找出最佳的方法。
- 使用 EXPANIN 语句让 MySQL 解释它将如何执行一条 SELECT 语句。
- 一般来说,存储过程执行得比一条一条地执行其中的各条 MySQL 语句快。
- 应该总是使用正确的数据类型。
- 决不要检索比需求还要多的数据。换言之,不要用
SELECT *(除非你真正需要每个列)。 - 有的操作(包括 INSERT)支持一个可靠的 DELAYED 关键字,如果使用它,将把控制立即返回给调用程序,并且一旦有可能就实际执行该操作。
- 在导入数据时,应该关闭自动提交。你可能还想删除索引(包括 FULLTEXT 索引),然后在导入完成后再重建它们。
- 必须索引数据库以改善数据检索的性能确定索引什么不是一件微不足道的任务,需要分析使用的 SELECT 语句以找出重复的 WHERE 和 ORDER BY 子句。
如果一个简单的 WHERE 子句返回结果所花的时间太长,则可以断定其中使用的列(或几个列)就是需要索引的对象。 - 你的 SELECT 语句中有一系列复杂的 OR 条件吗?通过使用多条 SELECT 语句和连接它们的 UNION 语句,你能看到极大的性能改进。
- 索引改善数据的性能,但损害数据插入、删除和更新的性能。
如果你有一些表,它们收集数据且不经常被搜索,则在有必要之前不要索引它们。(索引可根据需要添加和删除) - LIKE 很慢。一般来说,最好是使用 FULLTEXT 而不是 LIKE。
- 数据库是不断变化的实体。一组优化良好的表一会儿后可能就面目全非了。由于表的使用和内容的更改,理想的优化和配置也会改变。
- 最重要的规则就是,每条规则在某些条件下都会被打破。
注意
- 何时使用单引号?单引号用来限定字符串。如果将值与串类型的列进行比较,则需要限定引号。用来与数值列进行比较的值不需要引号。
- SQL 是不区分大小写的。
- SQL 语句以
;结束。 - SQL 语句中的空格会被忽略,将 SQL 语句分成多行更容易阅读和调试;